

Introduzione
Chiamarla intelligenza artificiale sarebbe riduttivo, perché parliamo di un’opera che ha coinvolto ricercatori universitari a lavoro dal 2015, per lo sviluppo di un algoritmo open source generatore di immagini (text to image) chiamato latent diffusion, uscito nel mercato solo nel 2022,
che ha successivamente raccolto più di 100 milioni di dollari in donazioni per la ricerca ed il suo miglioramento.
In assoluto l’AI più apprezzata dal settore, particolarmente nella fascia dei professionisti, non solo grazie alla sua forma commerciale gratuita, in grado di coinvolgere la stessa massa per il suo miglioramento, principalmente grazie ai parametri di controllo che permettono realmente all’essere umano di comandarla a piacere, sfruttandola al meglio e con risultati impareggiabili.
Per comprendere al meglio la rivoluzione di XL dobbiamo fare un passo a ritroso nel tempo.

Come viene allenata una text to image
Per generare una immagine da un testo i nostri calcolatori hanno bisogno di sapere cosa stanno facendo, cosa gli viene effettivamente richiesto.
Nel 2020 ci venne proposto di unirci alla ricerca per lo sviluppo di stability, l’algoritmo di stable diffusion.
Ci veniva richiesto di allenare l’algoritmo inserendo le nostre immagini, descrivendo minuziosamente: quale era il soggetto, la sua composizione, posa, prospettiva, illuminazione, scena, cosa stava facendo, come interagiva con l’ambiente circostante, pure in cosa consisteva l’ambiente, eccetera.
Migliore e più precisa era una descrizione allegata all’immagine, migliore era l’allenamento.
Questo set di dati descrittivi, collegato all’immagine, andava a nutrire il data set dell’intelligenza artificiale (creandone dei modelli); la AI sarà in grado, successivamente, di riprodurre il mio soggetto con infinite varianti generate tramite diffusione incrociata con altri dati.
Inizialmente le prime immagini di allenamento erano in bassa risoluzione, data la relativa scarsità di potenza di calcolo hardware dei singoli ricercatori, nonostante fossimo tutti professionisti armati di personal computer o workstation top di gamma.
La rivoluzione vera e propria la vivremo adesso proprio con l’uscita di XL, che grazie ai fondi raccolti per la ricerca ha triplicato e migliorato la velocità di generazione di immagini in alta risoluzione, nutrendosi di dati altrettanto qualitativi.

Cosa differenzia SD da MidJourney
Il principale competitor nel mercato si chiama MidJourney, un’intelligenza artificiale che è stata privatizzata e lavora solo in remoto, tramite abbonamento mensile, sfruttando la potenza di calcolo di grosse server farm.
MidJourney continua ad essere la più apprezzata dal mercato “entry level” (persone senza reali competenze) per la sua facilità d’utilizzo, perché non richiede investimenti in termini di tempo, studio o macchinari costosi.
Tuttavia MidJourney presenta una serie infinita di limiti, che sono stati risolti da tempo grazie a stability.
Possiamo usare stability online (gratuitamente), su server in remoto, come si farebbe con MidJourney,
ma possiamo installare la stessa in locale, scaricare dataset a piacere, implementarla con decine di estensioni, avere il controllo totale di ogni parametro, allenarla con nuovi modelli personali: in sostanza l’uomo è finalmente in grado di plasmare la macchina al proprio servizio, per le sue specifiche esigenze.
Oltre al fatto che Stable Diffusion non si limita a generare immagini. Andiamo quindi ad elencare tutte le sue potenzialità.
Allenare il proprio data set, img2img
Così come venne fatto dai ricercatori, oggi installando le estensioni Lora e Dreambooth è possibile allenare localmente la AI.
Servono almeno 15-20 immagini pertinenti e coerenti, che potrebbero, per esempio, essere scatti del mio volto in pose e scene differenti.
Partendo da questo materiale dobbiamo andare a descrivere testualmente ogni immagine.
Seguiranno delle prime fasi di interazione fra il materiale fornito e delle prompt testuali, per testare l’algoritmo di diffusione.
Ogni risultato deve essere valutato, eventualmente scartato, o selezionato.
Le immagini selezionate vanno nuovamente descritte, con le varianti ottenute, quindi andranno svolte altre fasi di interazione e diffusione.
Una volta raggiunta la perfezione, sempre nel caso del mio volto o di qualsiasi altro soggetto, avremo creato un “modello”, un dato che potrà essere replicato infinite volte semplicemente venendo nominato nella mia richiesta di generazione.
Voglio il mio volto dipinto da Pablo Picasso? Perché no. E perché non mettermi nel razzo che è sbarcato nella luna? Le possibilità diventano infinite.
Altrimenti, saltando il passaggio di allenamento, possiamo ridurre i tempi (ottenendo risultati meno precisi) tramite le funzioni image 2 image: carico una singola immagine, la descrivo, chiedo che vada ad interagire con una prompt testuale.
Anche in questo caso, riusciamo comunque ad avere un discreto controllo della situazione, chiedendo alla macchina quanto fondere le due immagini, con un parametro proporzionale che va da zero ad uno.

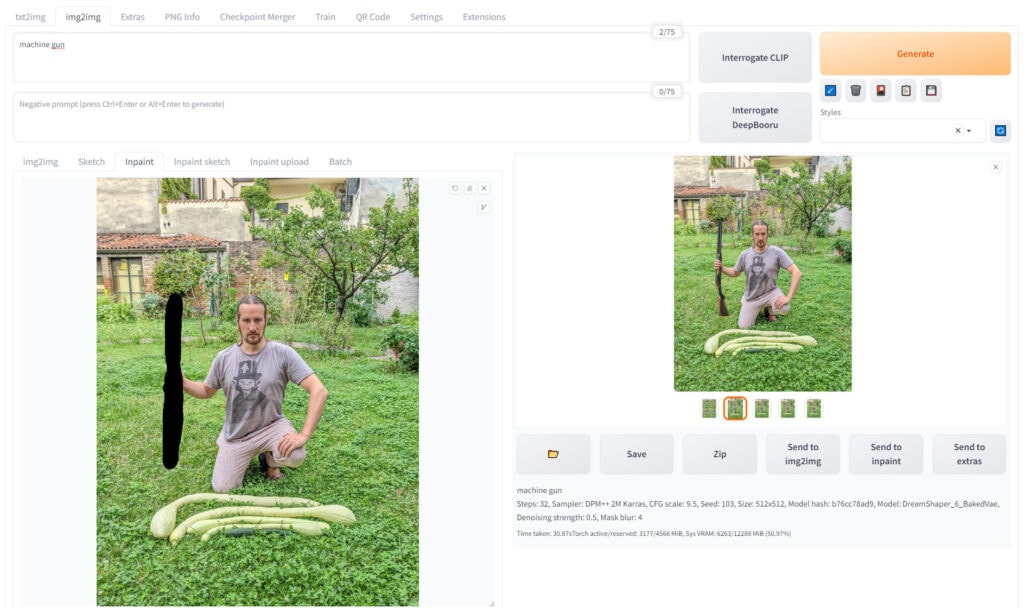
InPainting e OutPainting
Ulteriori casi d’uso per la modifica dell’immagine tramite img2img sono offerti da numerose implementazioni front-end del modello Stable Diffusion.
L’inpainting comporta la modifica selettiva di una porzione di un’immagine esistente delineata da una maschera di livello fornita dall’utente, che riempie lo spazio mascherato con il contenuto appena generato in base al prompt fornito.
OutPainting al contrario riempie la scena creando contenuti coerenti o a piacere al di fuori della mia immagine di partenza.
ControlNet
L’estensione che ha rivoluzionato la stessa AI, la più apprezzata ed utilizzata, si chiama ControlNet e rende possibile utilizzare schizzi, contorni, mappe di profondità o pose umane per controllare i modelli di diffusione in maniera mai vista prima.
Questa nuova architettura gestisce i modelli di diffusione incorporando condizioni aggiuntive.
Duplica i pesi dei blocchi della rete neurale in una copia “bloccata” e una copia “addestrabile”.
La copia “addestrabile” apprende la condizione desiderata, mentre la copia “bloccata” conserva il modello originale.
Questo approccio garantisce che l’addestramento con piccoli set di dati di coppie di immagini non comprometta l’integrità dei modelli di diffusione pronti per la produzione.
Probabilmente ricordate quegli spassosi meme delle immagini con persone a sette o otto dita per mano.
Non solo si è riusciti a dire alla AI di mantenere quelle cinque dita “originali” dell’essere umano,
con controlnet siamo anche riusciti a metterle in posa a piacere.
E se volessimo parlare di altri casi d’uso creativi di questa estensione? Vi cito i nuovi QR, in grado di mantenere il perfetto contrasto di luminosità fra il bianco e nero di un QR ordinario, generandovi un contenuto visivo, pura grafica al cardiopalma, al suo interno.


Da immagine a video, da video a video
Se non eravate convinti delle potenzialità di stability, siamo pronti a tirar fuori un altro asso dalla manica.
Dal momento in cui stable diffusion è opensource, avrete visto sicuramente migliaia di video ed altrettante applicazioni per smartphone in grado di generarne.
Queste applicazioni, a pagamento, non fanno altro che offrire e replicare le potenzialità di stability, offrendo un servizio basato su server remoti.
Quindi si parte tutti dalle stesse estensioni, come ControlNet-M2M, ControlNet img2img, Mov2mov, SD-CN Animation, Temporal Kit; chi ha le competenze ed abbastanza potenza di calcolo può generare il tutto comodamente dal computer di casa, gratuitamente.
Sfruttando quando abbiamo appena imparato, siamo in grado di allenare un nostro modello, creandone un dato replicabile.
Il mio dato andrà ad interagire con un secondo dato in forma di video.
Posso riprendermi mentre ballo e chiedere alla AI di farmi diventare una statua greca che balla, un gatto, una pantera.
Posso animare un quadro, posso vestire Rihanna come Michael Jackson e farla salire sul palco dei Queen per cantare Bohemian Rhapsody (mamma mia!).
In base ai parametri selezionati, affinando il tiro attraverso l’uso di queste estensioni, i risultati sono più o meno precisi, quindi come per ogni operazione, tornando punto a capo, servono tempo, studio, dedizione e pazienza.
Risorse e link di riferimento
Se siete interessati a scoprire SDXL per conto vostro, lascio una serie di link ufficiali, pagine di apprendimento e community.
Le migliori università altrettanto hanno iniziato ad offrire percorsi ufficiali di formazione, ma potete trovarne anche di altro tipo, promossi da singoli professionisti o aziende.
Link ufficiali di Stable Diffusion
Canale discord per usare SDXL online: http://discord.gg/stablediffusion
Il più grande repository di modelli e dataset per SD: https://huggingface.co/
Corso di AI Arts con crediti universitari e certificazione internazionale:
Formazione gratuita online: https://www.youtube.com/@Aitrepreneur
Marco Natolli
Se hai bisogno di una consulenza per un progetto online


